Speech-driven 3D talking head animation seeks to generate realistic, expressive facial motions directly from audio. Most existing methods use only single-scale (i.e., frame-level) speech features and directly regress full-face geometry, ignoring the influence of multi-level cues (phonemes, words, utterances) on facial motions, often resulting in over-smoothed, unnatural movements. To address this, we propose HiSTalk, a hierarchical framework comprising a Coarse Motion Generator (CMG) that captures global facial trajectories via a Transformer on speech embeddings, and a Fine Motion Refiner (FMR) with two stages: HSF2S encodes frame-, phoneme-, word-, and utterance-level features into weighted sparse landmark displacements using a squeeze-and-excitation gating mechanism, and S2D lifts these offsets into dense 3D deformation fields via a multi-branch attention-fusion Transformer decoder. By fusing coarse guidance with fine-grained refinements, HiSTalk achieves precise lip-sync and rich expressiveness, outperforming state-of-the-art on VOCASET and BIWI.
Method Overview
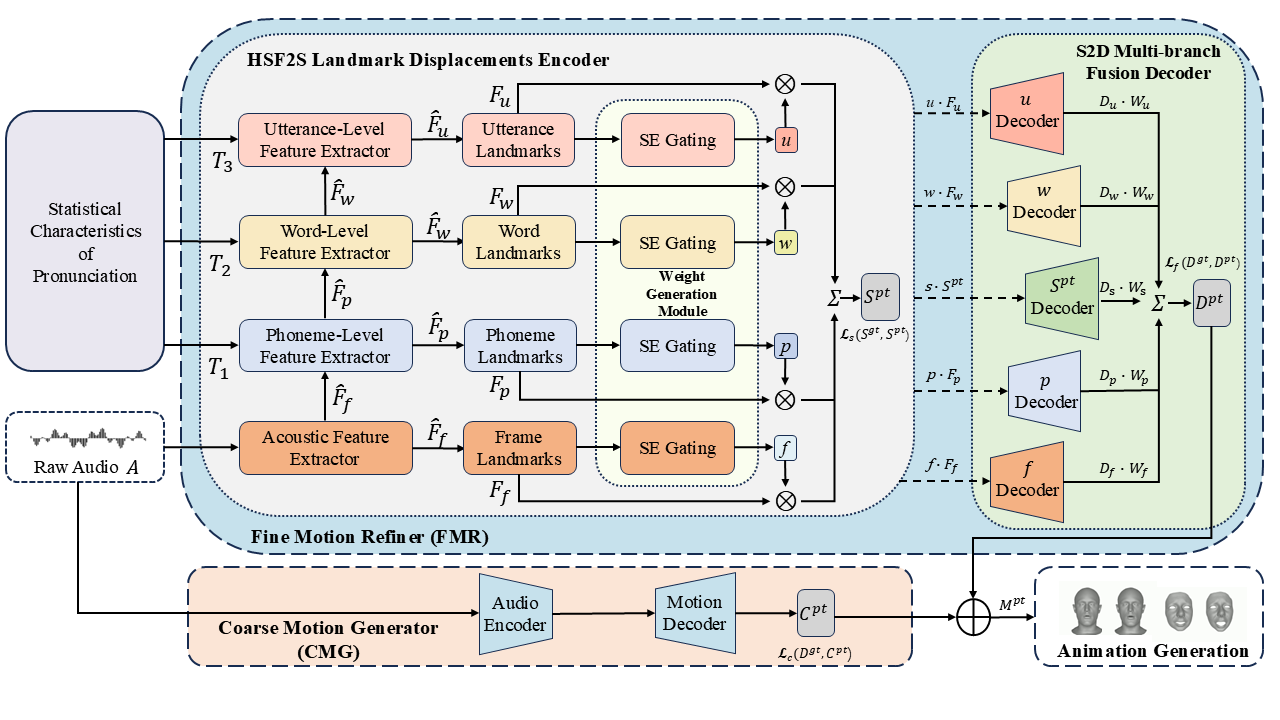
- Coarse Motion Generator (CMG): captures global facial displacements from audio via a Wav2Vec 2.0 encoder and a Transformer decoder.
- Fine Motion Refiner (FMR):
- HSF2S Encoder: extracts hierarchical speech features (frame, phoneme, word, utterance) using SpeechFormer++ blocks and applies squeeze-and-excitation gating to compute sparse landmark offsets.
- S2D Decoder: fuses sparse offsets into dense deformation fields with multi-branch attention-fusion Transformer decoders.